spark 는 jar를 박기 시작하면 무거워져서, 1MB 이상일 경우 docker 에서 적재하고 실행하는데에 오래걸림. 특히 운영환경에서 수백개, 수십개의 docker 를 띄우는 환경이라면, 더더욱 경량화에 신경써야 한다.
Apache Spark와 Iceberg를 통한 데이터 적재와 Trino의 MERGE 쿼리 활용
1. **환경 설정**
Docker와 Python 3.12 버전 - 생략.
2. **데이터 파이프라인 개요**
Apache Airflow, Spark, Trino를 활용해 데이터 파이프라인을 구축하는 방법에 대해 간단히 설명함. 각 툴의 역할은 다음과 같음.
- **Apache Airflow** : 작업 스케줄링과 관리.
- **Spark** : 대량의 데이터를 빠르게 처리하고 분석.
- **Trino** : SQL 쿼리를 사용해 데이터에 대한 빠른 질의 제공.
전체 아키텍처를 보면, Airflow가 작업을 트리거하고, Spark가 데이터를 처리하며, Trino가 그 결과를 쿼리함. 이 구조는

와 같이 데이터 파이프라인을 시각적으로 잘 보여줌.
3. **Iceberg와 데이터 테이블**
Iceberg는 대규모 데이터 세트를 효율적으로 관리할 수 있는 테이블 형식임. 데이터 스키마의 변경이 용이하고, 버전 관리가 가능해 데이터의 무결성을 보장함. Iceberg의 테이블은 S3 - spark or parquet to table 또는 external 테이블을 지정하여 세팅함
4. **MERGE 쿼리 이해하기**
Trino에서 MERGE 쿼리는 특정 조건에 따라 데이터를 업데이트하거나 삽입하는 데 사용됨. 특히, Iceberg 테이블과 함께 사용할 때 그 유용성이 더욱 극대화됨. MERGE 쿼리는 다음과 같은 기본 구조를 가짐:
** SQL :
MERGE INTO target_table AS target
USING source_table AS source
ON target.id = source.id
WHEN MATCHED THEN
UPDATE SET target.value = source.value
WHEN NOT MATCHED THEN
INSERT (id, value) VALUES (source.id, source.value);
데이터 업데이트와 인서트를 동시에 세팅하여 처리하나, 조회 조건이나 업데이트 조건에 따른 부하가 많이 걸릴수 있음에 유의.
다만 이번 개선 작업에서는 트랜잭션을 관리하기가 까다로워서, merge 쿼리를 통해 트랜잭션을 최대한 건드리지 않는 방식으로 진행함
5. **MERGE 쿼리 실행 예시**
이제 Python을 사용해 Trino에서 MERGE 쿼리를 실행하는 예시를 보여주겠음. 다음은 간단한 Python 스크립트로, Trino와 연결 후 MERGE 쿼리를 실행하는 방법임.
python
from trino import dbapi
conn = dbapi.connect(
host='trino-host',
port=8080,
user='your-username',
catalog='iceberg',
schema='your-schema'
)
cur = conn.cursor()
cur.execute("""
MERGE INTO recent_messages AS target
USING message_logs AS source
ON target.id = source.id
WHEN MATCHED THEN
UPDATE SET target.timestamp = source.timestamp
WHEN NOT MATCHED THEN
INSERT (id, timestamp) VALUES (source.id, source.timestamp);
""")
print(f"Executed: rows affected.")
이 코드를 실행하면,
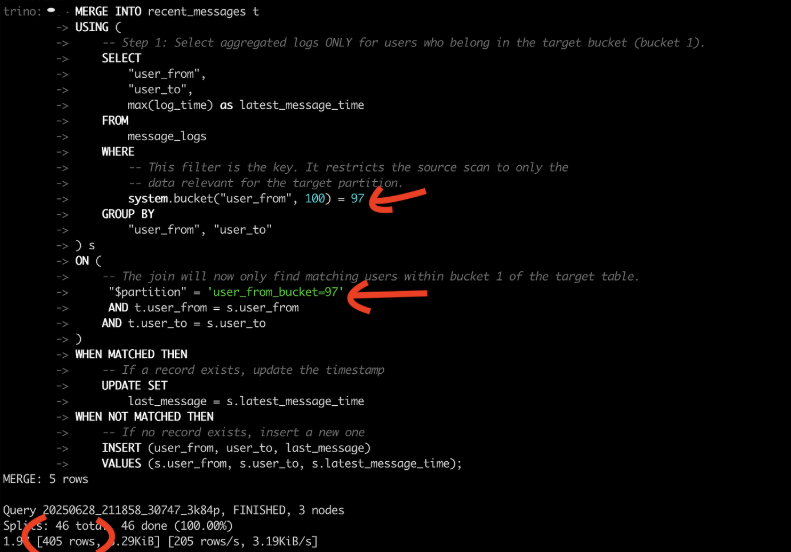
와 같이 쿼리 실행 결과도 확인 가능함.
6. **주의사항과 팁**
트랜잭션 오류를 피하기 위해서는 다음과 같은 팁을 따르는 것이 좋음.
- 데이터 타입과 스키마를 정확히 맞추는 것이 중요함.
- MERGE 쿼리를 실행하기 전에 데이터를 미리 확인할 것.
- 정기적으로 Iceberg 테이블의 메타데이터를 점검하고, Nessie와 같은 도구를 활용해 버전 관리할 것.
7. **관련 자료**
추가적으로 도움이 될 만한 자료를 아래에 링크해 두겠음.
- [Iceberg 데이터 적재 자동화](https://medium.com/@nsalexamy/automating-iceberg-data-ingestion-with-airflow-spark-and-trino-part-2-building-the-pyspark-a51a1f5f0660)
- [Trino를 활용한 Iceberg 테이블 작업하기](https://docs.aws.amazon.com/prescriptive-guidance/latest/apache-iceberg-on-aws/iceberg-trino.html)
- [GitHub 이슈 관련 MERGE 쿼리 실패](https://github.com/trinodb/trino/issues/26496)
**태그**
#Spark #Iceberg #Trino #데이터적재 #Python #Docker #데이터파이프라인
참고 : https://www.sktenterprise.com/bizInsight/blogDetail/dev/15086)
'PYTHON' 카테고리의 다른 글
| [Python] Pandas vs Dask (0) | 2024.05.30 |
|---|---|
| [Python] pycharm pro / django 환경 변수 (0) | 2023.05.16 |
| [Python] Python 프로젝트 세팅 및 Django 설정 (0) | 2023.03.18 |
| [Python] django ktx project 계획 (0) | 2023.02.19 |